The cell line is still the cell line I thought?
- Normal Liver Cells Found to Promote Cancer Metastasis to the Liver
- Nearly 80% Complete Remission: Breakthrough in ADC Anti-Tumor Treatment
- Vaccination Against Common Diseases May Prevent Dementia!
- New Alzheimer’s Disease (AD) Diagnosis and Staging Criteria
- Breakthrough in Alzheimer’s Disease: New Nasal Spray Halts Cognitive Decline by Targeting Toxic Protein
- Can the Tap Water at the Paris Olympics be Drunk Directly?
The cell line is still the cell line I thought?
The cell line is still the cell line I thought? When we are doing cell experiments, we often have such doubts. The cells have been used by so many people so many times. What cell line I thought I was working on now? Could someone accidentally write the name of this cell line into another name during the passage, and then pass it on?
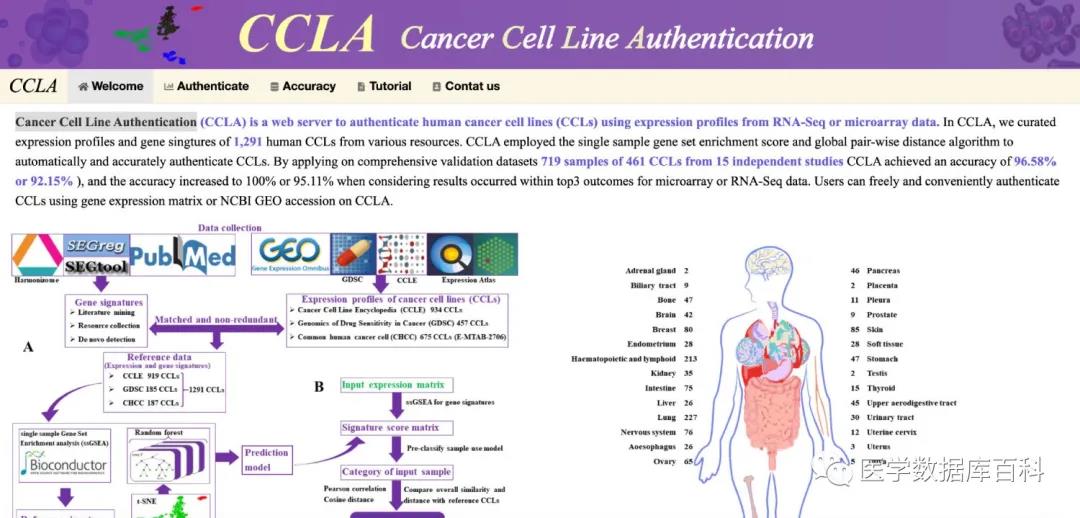
For this kind of problem, unless you buy a new cell, you will always have this doubt. Today,, we will introduce to you a newly published database. This database may solve everyone’s doubts. This database is called CCLA (Cancer Cell Line, http://bioinfo.life.hust.edu.cn/web/CCLA/).
Database principle
Before understanding the operation of this database, we can understand how this database is used for tumor cell line certification. The basic operation analysis process is similar to the process we make model predictions. So in fact, through this process, you can still understand how the general model predictions are done.
1. Background data collection
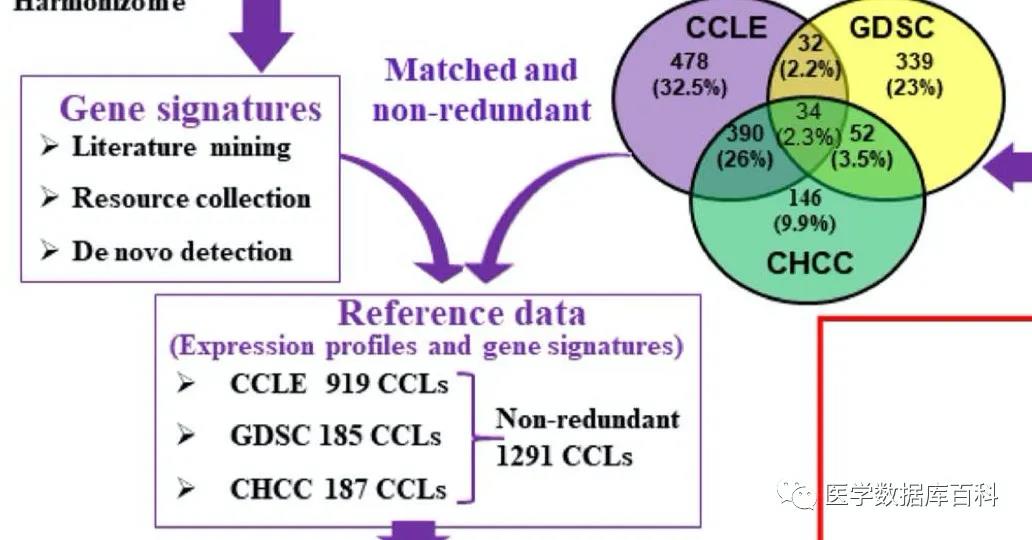
If you want to authenticate an unknown cell line. The priority is to collect known cell line expression data. Use these data as a background data set. This database collected the genome expression data of 1,291 cell lines in the three databases of CCLE, GDSC and CHCC as the background data set.
2. Build the model
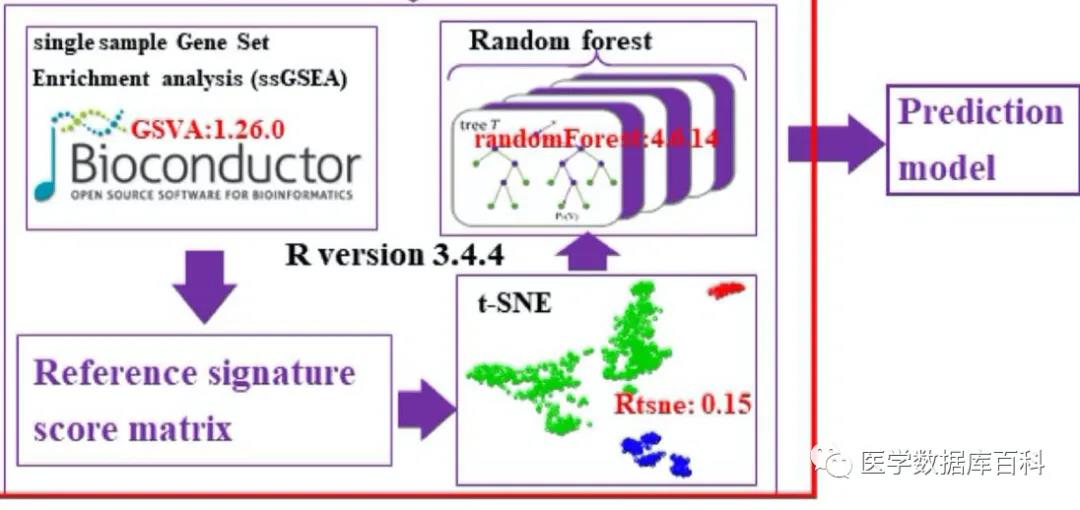
All predictions are based on previous data to build a model. After this database has collected the above data, the next step is to build the model. Because the expression data of the genome used by each cell line is different. So it needs to be standardized. The database uses the ssGSEA algorithm to standardize the expression data of all cell lines, and further uses the random forest method to construct a prediction model.
3. Data prediction
After the model is constructed, cell line prediction can be performed. The cell line prediction data uses the expression profile chip of the cell line or the expression data of next-generation sequencing. We need to submit relevant expression data. Then the database will standardize itself first, and then use the model to make predictions.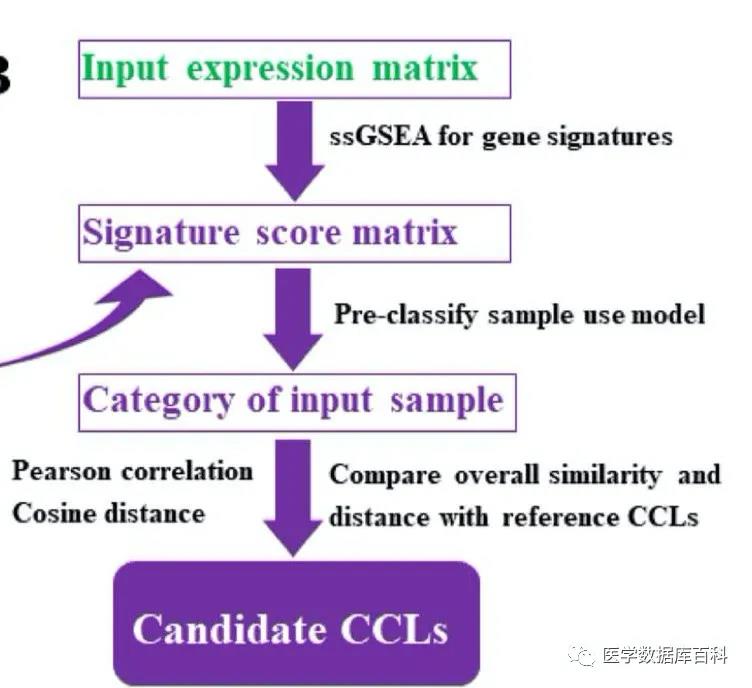
Database usage
Introduce the basic forecasting principles for the database. Then the use of the database is simple. We can predict the type of cell line in three steps.
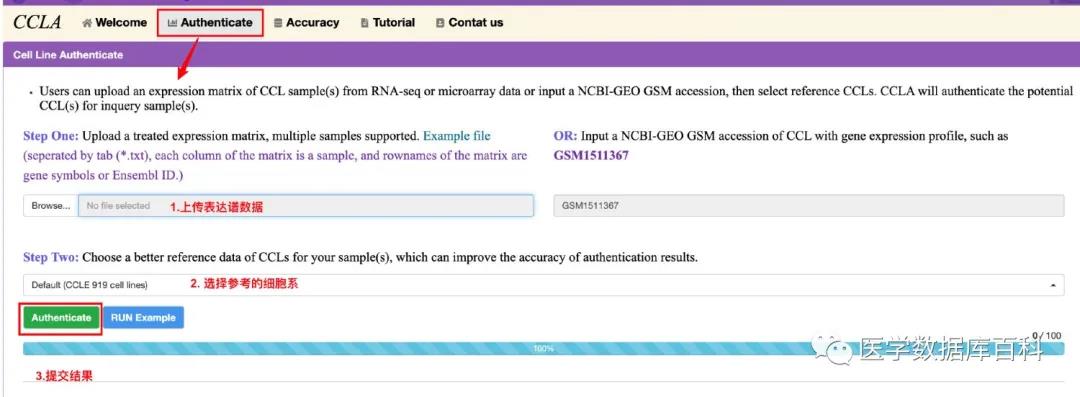
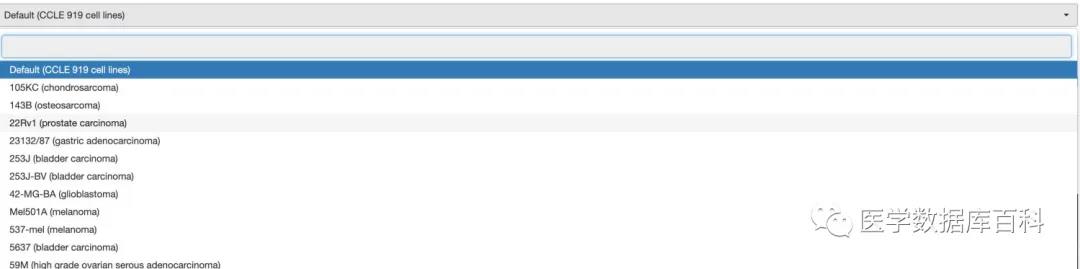
Among the predicted cell lines, we can choose more than 900 cell lines like CCLE to predict together. At the same time, a single cell line can also be selected for prediction.
Interpretation of results
For the results of the database, first, the database will show a summary of what each sample is most likely to be.
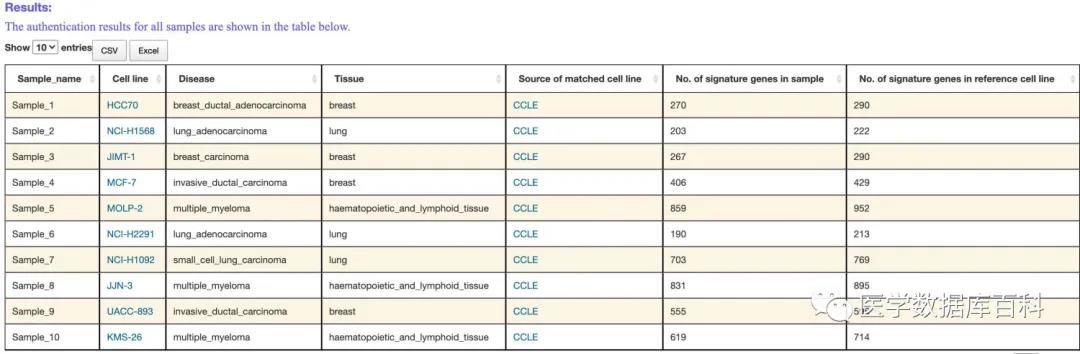
Secondly, there will be a detailed result for the information of each sample, including the top five possible cell lines. If our cell line is most likely not the target cell line, here you can see if there are any of the top five . After all, the results are still biased.
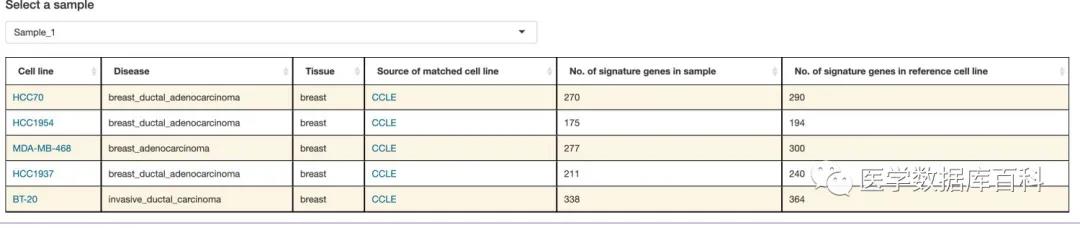
Sum up:
The above is all related things of this database. When it comes to the database, because it needs to provide data on the expression profile of this cell line, relatively speaking, there is still a certain threshold. However, as the price of sequencing drops, there should basically be sequencing results of its own cell lines.
Another thing to note is that we should actually check whether this database contains the cell line we want to verify before using it. If not, then there will definitely be no results.
(source:internet, reference only)
Disclaimer of medicaltrend.org