ICLR 2021 Outstanding Paper Award is released!
- Normal Liver Cells Found to Promote Cancer Metastasis to the Liver
- Nearly 80% Complete Remission: Breakthrough in ADC Anti-Tumor Treatment
- Vaccination Against Common Diseases May Prevent Dementia!
- New Alzheimer’s Disease (AD) Diagnosis and Staging Criteria
- Breakthrough in Alzheimer’s Disease: New Nasal Spray Halts Cognitive Decline by Targeting Toxic Protein
- Can the Tap Water at the Paris Olympics be Drunk Directly?
ICLR 2021 Outstanding Paper Award is released!
- Should China be held legally responsible for the US’s $18 trillion COVID losses?
- CT Radiation Exposure Linked to Blood Cancer in Children and Adolescents
- Can people with high blood pressure eat peanuts?
- What is the difference between dopamine and dobutamine?
- What is the difference between Atorvastatin and Rosuvastatin?
- How long can the patient live after heart stent surgery?
ICLR 2021 Outstanding Paper Award is released! The selection process for this outstanding paper is extremely rigorous.
On April 1, 2021, ICLR 2021 outstanding papers are freshly published! Among the 860 high-quality papers accepted at ICLR this year, 8 papers stood out and were awarded the ICLR 2021 Outstanding Paper Award.
The selection process for this outstanding paper is extremely rigorous. First, the outstanding paper review committee will give a list of candidate papers based on the review comments when the paper is accepted; then, the outstanding paper review committee will further review the papers in the list.
Experts not only need to evaluate the technical quality of the papers, but also Also evaluate the possible impact of the paper. This impact includes introducing new research perspectives, opening up exciting new research directions, and making a strong contribution to solving important problems.
After the above-mentioned rigorous review process, it was finally determined that the 8 highest-ranked papers won the ICLR 2021 Outstanding Paper Award.
1.Beyond Fully-Connected Layers with Quaternions: Parameterization of Hypercomplex Multiplications with 1/n Parameters
- [Paper authors] Aston Zhang, Yi Tay, Shuai Zhang, Alvin Chan, Anh Tuan Luu, Siu Hui, Jie Fu
- [Organization] Amazon AWS, Google Research, ETH Zurich, Nanyang Technological University, Mila Lab
- [Thesis link] https://www.aminer.cn/pub/6008327b9e795ed227f5310e/?conf=iclr2021
[Abstract]
In recent years, some studies have demonstrated the success of representation learning in super-complex space. Specifically, the fully connected layer with quaternion (quaternion is four-dimensional supercomplex number) replaces the real-valued matrix multiplication in the fully connected layer with the Hamilton product of quaternion. This method uses only 1/4 In the case of learnable parameters, performance comparable to the previous method has been achieved in various applications.
However, the super-complex space only exists in a few predefined dimensions (four-dimensional, eight-dimensional, and sixteen-dimensional), which limits the flexibility of models that use super-complex multiplication. To this end, the author of this article proposes a parameterization method for super-complex multiplication, so that the model can learn multiplication rules based on data, regardless of whether such rules are predefined.
In this way, the method proposed in this paper not only introduces the Hamilton product, but also learns to operate on any n-dimensional hypercomplex space. Compared with the corresponding fully connected layer, the PHM layer proposed in this paper uses any 1/n of learnable parameters, which achieves greater architectural flexibility.
In experiments, the author of this paper applied the PHM layer proposed in this paper to the LSTM and Transformer models in natural language reasoning, machine translation, text style transfer, and subject-verb agreement tasks, verifying the flexibility and effectiveness of the method.
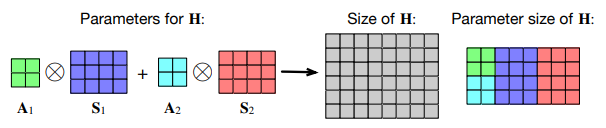
Figure 1: Schematic diagram of the PHM layer.
2.Complex Query Answering with Neural Link Predictors
[Papers authors] Erik Arakelyan, Daniel Daza, Pasquale Minervini, Michael Cochez
[Organization] University College London, Vrije Universiteit Amsterdam, University of Amsterdam, Elsevier Discovery Laboratory
[Thesis link] https://www.aminer.cn/pub/5fa9175f91e011e83f7407f4/?conf=iclr2021
[Code link] https://github.com/uclnlp/cqd
[Abstract] Neural link predictors are very useful for identifying missing edges in large-scale knowledge graphs. However, it is not clear how to use these models to answer more complex queries involving multiple domains (for example, in the case of considering missing edges, processing uses logical conjunction (∧), disjunction (∨), existential quantifier ( ∃) query).
In this article, the author proposes a framework that can efficiently answer complex queries on incomplete knowledge graphs. The author of this article converts each query into an end-to-end differentiable target, and uses a pre-trained neural link predictor to calculate the true value of each atom. The author of this article further analyzed two solutions to optimize the goal change (including gradient-based search and combined search.
The experimental results show that the method proposed in this paper achieves a better method than the current one (a “black box” neural model trained with millions of generated queries without using large-scale and diverse query set training. ) Higher accuracy rate.
In the case of using several orders of magnitude less training data, the model proposed in this paper has achieved a relative performance improvement of Hits@3 ranging from 8% to 40% on various knowledge graphs containing factual information. Finally, the author of this article points out that according to the intermediate solution of each complex query atom, the output of the model is interpretable.

Figure 2: The intermediate variable assignment and sorting results of the two queries obtained by CQD-Beam.
3.EigenGame: PCA as a Nash Equilibrium
[Paper authors] Ian Gemp, Brian McWilliams, Claire Vernade, Thore Graepel
【Organization】DeepMind
[Thesis link] https://www.aminer.cn/pub/5f77013191e011f31b980711/?conf=iclr2021
[Code link] https://github.com/uclnlp/cqd
[Abstract] In this article, the author proposes a novel perspective, which regards principal component analysis (PCA) as a competitive game, in which each approximate feature vector is controlled by a game player, and the participant’s The goal is to maximize their utility function.
The author of this paper analyzes the characteristics of the PCA game and the effect of gradient-based update behavior. In the end, the author proposes an algorithm that combines the elements of Oja learning rules with the generalized “Klemschmidt” orthogonalization, which naturally realizes decentralized and parallel computing through message passing.
Through experiments on large-scale image data sets and neural network activation, the author demonstrated the scalability of the algorithm. The author points out that this new perspective on PCA as a microgame will lead to further algorithm development and a deeper understanding.
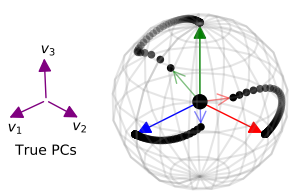
Figure 3: EigenGame guides each vector on the unit sphere at the same time.
4.Learning Mesh-Based Simulation with Graph Networks
[Paper authors] Tobias Pfaff, Meire Fortunato, Alvaro Sanchez-Gonzalez, Peter W. Battaglia
【Organization】DeepMind
[Thesis link] https://www.aminer.cn/pub/5f7ee8c991e011a5faf0ffad/?conf=iclr2021
[Code link] https://sites.google.com/view/meshgraphnets
【Abstract】In many science and engineering disciplines, grid-based simulation is the core of modeling complex physical systems. Grid characterization can support powerful numerical integration methods, and its resolution can achieve a good balance between accuracy and efficiency. However, the cost of high-dimensional scientific simulation is extremely high, and it is often necessary to adjust the solver and parameters separately for each system to be studied.
In this article, the author proposes “MeshGraphNets”, which is a framework for learning grid-based simulations using graph neural networks. By training the model proposed in this paper, we can make it transmit messages on the grid graph and adapt to the discretization of the grid during the feedforward simulation process. Experimental results show that the model proposed in this paper can accurately predict the dynamics of many physical systems (including aerodynamics, structural mechanics and cloth). The adaptability of the model allows us to learn resolution-independent dynamics and can be extended to more complex state spaces during testing. The method proposed in this paper is also very efficient, running at test time 1-2 orders of magnitude faster than training simulation. The method proposed in this paper expands the range of problems that the neural network simulator can operate, and can effectively improve the efficiency of complex and scientific modeling tasks.
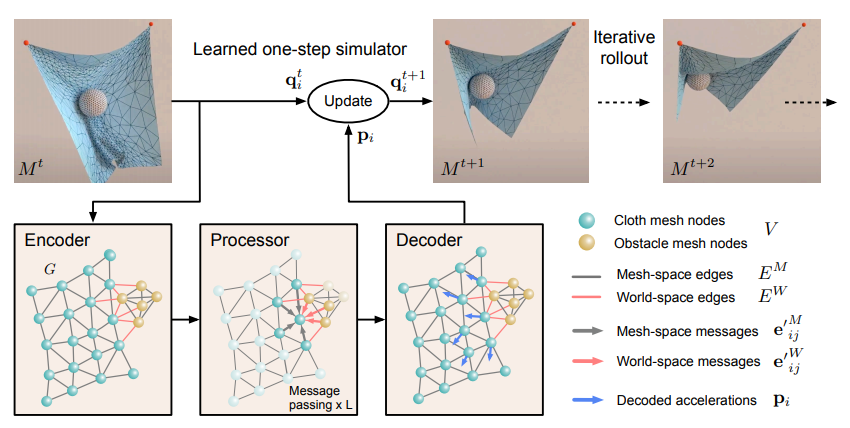
Figure 4: MeshGraphNets operation in the SphereDynamic domain.
5.Neural Synthesis of Binaural Speech From Mono Audio
[Paper authors] Alexander Richard, Dejan Markovic, Israel D. Gebru, Steven Krenn, Gladstone Alexander Butler, Fernando Torre, Yaser Sheikh
[Organization] Facebook Reality Lab
[Thesis link] https://www.aminer.cn/pub/600830f39e795ed227f53086/?conf=iclr2021
[Code link] https://github.com/facebookresearch/BinauralSpeechSynthesis
【Abstract】This paper proposes a neural rendering method for two-channel sound synthesis, which can generate realistic and spatially accurate two-channel sound in real time. The network takes a single-channel sound source as input, synthesizes two-channel sound according to the relative position and direction of the listener with respect to the sound source, and outputs it. In the theoretical analysis, the author of this paper studies the deficiencies of the L2 loss of the original waveform, and introduces an improved loss function to solve the above deficiencies. Through empirical research, the author determined that the method proposed in this paper generates spatially accurate waveform output (measured by real records) for the first time, and is much better than existing methods in both quantitative and perceptual-based research.
Figure 5: Schematic diagram of the system.
6.Optimal Rates for Averaged Stochastic Gradient Descent under Neural Tangent Kernel Regime
[Paper authors] Alexander Richard, Dejan Markovic, Israel D. Gebru, Steven Krenn, Gladstone Alexander Butler, Fernando Torre, Yaser Sheikh
[Organization] The University of Tokyo, RIKEN Advanced Intelligence Project Center, Japan Science and Technology Agency
[Thesis link] https://www.aminer.cn/pub/5ef3247a91e0110c353da898/?conf=iclr2021
[Abstract] In this article, the author analyzes the convergence of the average stochastic gradient descent of the over-parameterized two-layer neural network for the regression problem. In recent years, some research work has pointed out that the neurotangent nucleus (NTK) plays an important role. These works have studied the global convergence of gradient-based methods under the NTK mechanism, in which we can almost describe the learning mechanism of parameterized neural networks through the relevant regenerative Hilbert space (RKHS). However, the convergence rate analysis under the NTK mechanism is still very promising. In this article, the author uses the objective function and the complexity of RKHS related to NTK to show that the average gradient descent can reach the minimax optimal convergence rate and can converge globally. In addition, the author also pointed out that under certain conditions, through the smooth approximation of the ReLU network, the objective function specified by the NTK of the ReLU network can be learned with the optimal convergence rate.
7. Rethinking Architecture Selection in Differentiable NAS
[Papers authors] Ruochen Wang, Minhao Cheng, Xiangning Chen, Xiaocheng Tang, Cho-Jui Hsieh
[Organization] University of California, Los Angeles, Didi Artificial Intelligence Laboratory
[Thesis link] https://www.aminer.cn/pub/600834609e795ed227f53207/?conf=iclr2021
【Abstract】Due to its search efficiency and simplicity, differentiable neural architecture search (NAS) is currently one of the most popular neural architecture search methods. We use gradient-based algorithms to simultaneously optimize model weights and architecture parameters in the weight-sharing supernet to achieve differentiable neural architecture search.
At the end of the search phase, we will select the operation with the largest architecture parameter to get the final architecture.
Among them, the implicit assumption is that the value of the architecture parameter reflects the intensity of the operation. Although there is a lot of research work discussing the optimization of supernet, few studies have focused on the architecture selection process.
The author of this article shows through experiments and theoretical analysis: the number of architecture parameters does not necessarily indicate how much the operation contributes to the performance of the supernet.
In this article, the author proposes an alternative to perturbation-based architecture selection, which can directly measure the impact of each operation on the supernet. The author re-evaluated several differentiable NAS methods through the architecture selection strategy proposed in this article, and found that this strategy can always extract a significantly improved architecture from the underlying supernet.
In addition, the author found that the architecture selection strategy proposed in this paper can greatly improve several failure modes of DARTS, which indicates that the lack of generalization capabilities observed in DARTS is due to the incomplete selection of architecture based on scale. It is due to the optimization problem of the supernet.

Figure 6: Perturbation-based architecture selection
8. SCORE-BASED GENERATIVE MODELING THROUGH STOCHASTIC DIFFERENTIAL EQUATIONS
[Paper author] Yang Song
[Organization] Stanford University, Google Brain
[Thesis link] https://www.aminer.cn/pub/5fc4cfdf91e011abfa2faf94/?conf=iclr2021
[Abstract] It is easy to generate noise from data, and the process of generating data from noise is called formal modeling. The author of this paper proposes a stochastic differential equation (SDE), which smoothly converts the complex data distribution into a known prior distribution by slowly injecting noise; in addition, the author also proposes a corresponding reverse time SDE , Which converts the prior distribution back to the data distribution by slowly removing the noise. Crucially, the reverse time SDE only relies on the temporal gradient field (ie, fraction) of the perturbed data distribution.
By taking advantage of score-based generative modeling, we can use neural networks to accurately estimate these scores and use a numerical SDE solver to generate samples. In this article, the author explains that the framework encapsulates the previous methods of score-based generative modeling and diffusion probability modeling, resulting in a new sampling process and modeling capabilities.
Specifically, the author introduced a “predictor-corrector” framework to correct errors in the evolution of discretized reverse time SDE. Next, the author also derives an equivalent divine regular differential equation, which samples from the same distribution as SDE, and supports accurate likelihood calculations, which improves sampling efficiency.
In addition, the author proposes a new method to solve the inverse problem of the score-based model, and conducts experiments on class condition generation, image inpainting and coloring tasks.
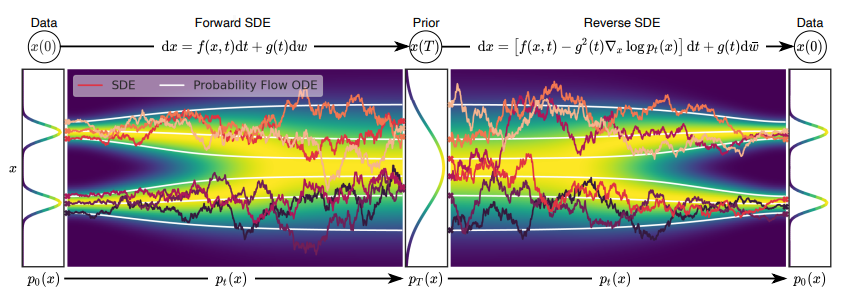
Figure 7: Construct a score-based generative model through stochastic differential equations
ICLR 2021 Outstanding Paper Award is released!
ICLR 2021 Outstanding Paper Award is released!
(source:internet, reference only)
Disclaimer of medicaltrend.org